
XMLで書かれた防災情報ページをPythonでブラウザに抽出する方法
XMLで書かれた防災情報ページをPythonでブラウザに抽出する方法について簡単に書いていこうと思います。
都道府県や市区町村のHPには災害情報や防災情報が書かれているページが存在します。例えば私が住んでいる横浜市では、HPの右上に防災や震災関連の情報が描かれています。
(引用:横浜市HPより)
そこから更に下層ページに進んで行くと「防災関連データ」というページが存在します。ページの冒頭には“横浜市では、防災アプリやWebページで利用していただくため防災関連施設の情報をXML形式で公開しています。是非ご活用ください。”という記載があります。

(引用:横浜市HPより)
防災に関するWebサービスを制作するために必要となる避難所等のデータをXML形式で提供していて、防災情報を普及しようとしているのですね。今回はこの防災のXML情報について、Pythonを活用してブラウザ上に表示する方法について簡単に書いていこうと思います。
目次
なぜPythonを活用してXML情報を取得するのか
特に深い理由はありません。もともと私はPHPを使ってサイト制作をすることが多く、PHPを使ってXMLを取得することが多かったのですが、最近になってAIと防災を関連付けたサービスを作りたいなと思い 、AIに強いPythonにはまっているので、 練習を兼ねてPythonで災害のXML情報を取得してみました。
横浜市の防災情報XMLデータの何を取得するのか
横浜市の防災関連データのサイトを見てみると、「地域防災拠点」「津波避難施設」「災害給水所」「帰宅困難者一時滞在施設」の4つの情報をXMLで提供していました。
日本語だけでなく、英語、中国語 (簡体字、繁体字)、ハングル、スペイン語、ポルトガル語と予想以上にたくさんの言語に対応するデータを提供していて驚きました。やはり横浜は外国人の観光客や居住者が多いことから他言語対応が必要になっているのかもしれません。
今回はこの中の「津波避難施設」の「日本語」のデータだけをブラウザ上で表示するにはどうすれば良いのか書いていこうと思います。
①XMLデータの取得
まず何はともあれXMLにどのようにデータが格納されているのか見ていこうと思います。おもむろに「津波避難施設」のリンクをクリックしてみると、ZIP形式でXML情報のダウンロードが始まります。ファイルを開いてみると下記のような構造になっています。
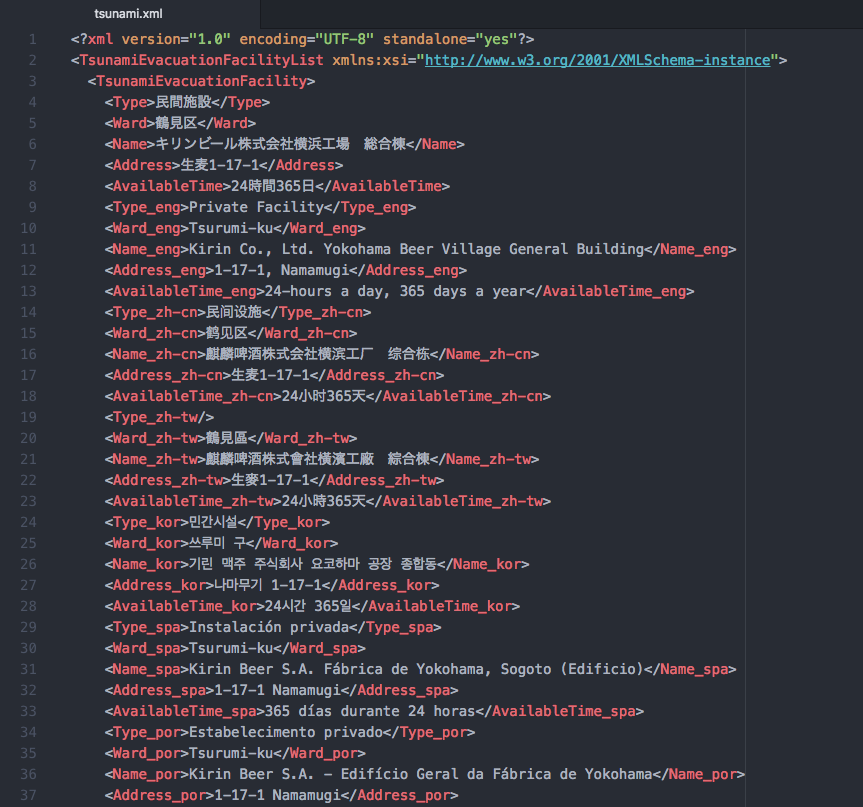
“Ward”の中に津波避難所のある“区”の情報が書かれており、”Name”の中に施設の名前、”Address”の中に所在地の詳細住所が書かれていることが分かります。とりあえず大量にある情報の中から、これらの情報をPythonで取得しようと思います。
②使用するPythonライブラリ
データを取得したりするためにBeautifulSoupとrequestを使用して、Pythonコードをブラウザに表示するためにflaskを使用したいと思います。これらをインストールしていない人は事前にインストールしておく必要があります。
②ソースコードの記入
では早速ソースコードを記入していこうと思います。完成系は下記のものになります。
from bs4 import BeautifulSoup
import urllib.request as req
import os.path
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def index():
savename = "tsunami.xml"
xml = open(savename, "r", encoding="utf-8").read()
soup = BeautifulSoup(xml, 'html.parser')
info = {}
for i in soup.find_all("tsunamievacuationfacility"):
name = i.find('name').string
ward = i.find('ward').string
address = i.find('address').string
if not (ward in info):
info[ward] = []
info[ward].append(name)
info[ward].append(address)
lastout = []
for ward in info.keys():
lastout.append(ward)
for name in info[ward]:
lastout.append(name)
lastout.append(address)
return render_template('index.html', lastout=lastout)
if __name__ == '__main__':
app.debug = True
app.run(host='0.0.0.0', port=831)
先ほど横浜市のHPからダウンロードしたXMLファイルはこのファイルと同階層に置いてください。ターミナルからこのPythonファイルを実行して、http://0.0.0.0:831/にアクセスすると下記のように取得したXML情報を表示することができました。

あとはこの表示内容をそれっぽく整えていけば横浜市の津波避難所を案内するWebサービスにデータを活用できそうです。
少しソースコードを詳しく見ていこうと思います。
③XMLから欲しいデータのみを取得する
savename = "tsunami.xml"
xml = open(savename, "r", encoding="utf-8").read()
soup = BeautifulSoup(xml, 'html.parser')
info = {}
for i in soup.find_all("tsunamievacuationfacility"):
name = i.find('name').string
ward = i.find('ward').string
address = i.find('address').string
if not (ward in info):
info[ward] = []
info[ward].append(name)
info[ward].append(address)
lastout = []
for ward in info.keys():
lastout.append(ward)
for name in info[ward]:
lastout.append(name)
lastout.append(address)
return render_template('index.html', lastout=lastout)
冒頭でBeautifulSoupを活用してXMLのデータを読み込んで、そこから欲しいデータであるname、word,addressを抽出しています。それをすべてlastoutの中に入れ込んでいます。ブラウザ上で綺麗に表示したい場合にはこの部分を変えていく必要がありますが、今回はブラウザに情報を表示するところまでをご紹介したいので割愛します。
④ブラウザに取得したデータを表示する
次に取得したデータをブラウザに表示していこうと思います。今回はflaskを活用してPythonデータをブラウザに表示していきます。
app = Flask(__name__)
@app.route('/')
def index():
if __name__ == '__main__':
app.debug = True
app.run(host='0.0.0.0', port=831)
この部分ですね。Pytonファイルと同階層にtemplatesというフォルダを作成して、その中にindex.htmlのファイルを入れます。index.htmlのコード記載は、取得した情報を表示させたいところに変数である{{ lastout }}を記入するだけです。
今回はただ取得したデータをブラウザに表示させるだけなので、簡単にしておきます。
これでうまく横浜市に置いてあるXML形式の津波避難所情報をブラウザ上に表示させることができました。
あとはデータの表示方法やレイアウト、デザインを整えることで、津波防災拠点のウェブページを作ることができます。
ここからさらに発展させて提供できるWebサービス
Pythonの良いところはここから簡単にサービスをより発展させることができることだと思います。例えば津波避難所の情報は定期的に更新されていく可能性があります。新しく避難所として建物が追加されることもありますし、建物の老朽化が進んで避難所として機能しなくなった建物が削除されるかもしれません。
古い情報を掲載するわけにはいかないので、例えばクローリング機能を使いして、例えば1週間に1回はサイトにクローラーを巡回させて、津波避難所の情報が更新されていないか確認して、仮に更新されていたら避難所の情報を自動で更新させることもできます。
ほかにもPythonの醍醐味とも言えるAIから避難所の立地条件を分析してみたりすることも可能だと思います。
GoogleのTensorflowを活用した防災分野へのAIの活用についても随時ご紹介していこうと思います。